
I am a bit confused, dear reader, but the LLMs that Deepseek users – primarily here we are using the 8b model vs the 1.5b model. Here’s the answers:
8b model:
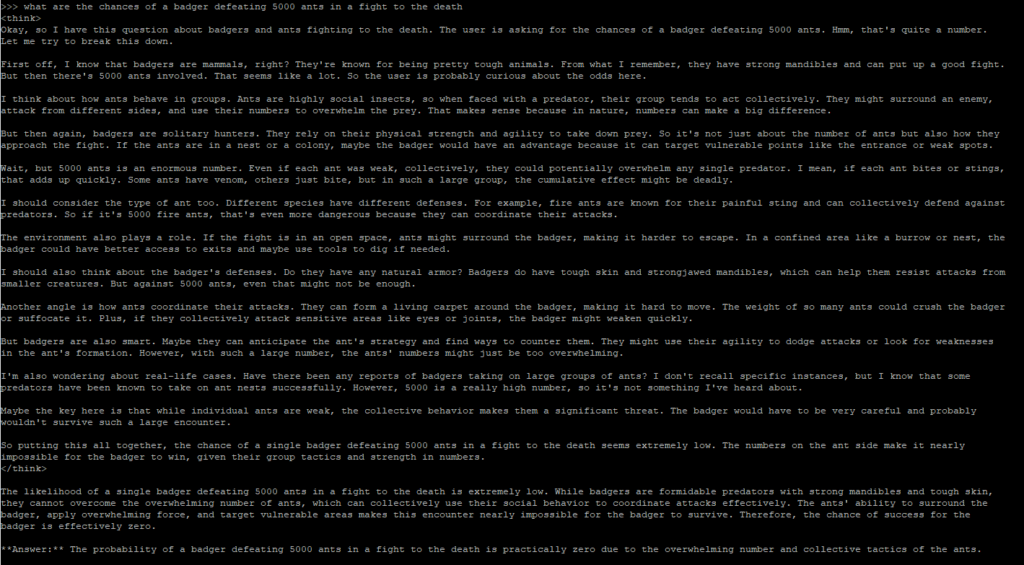
1.5b model:
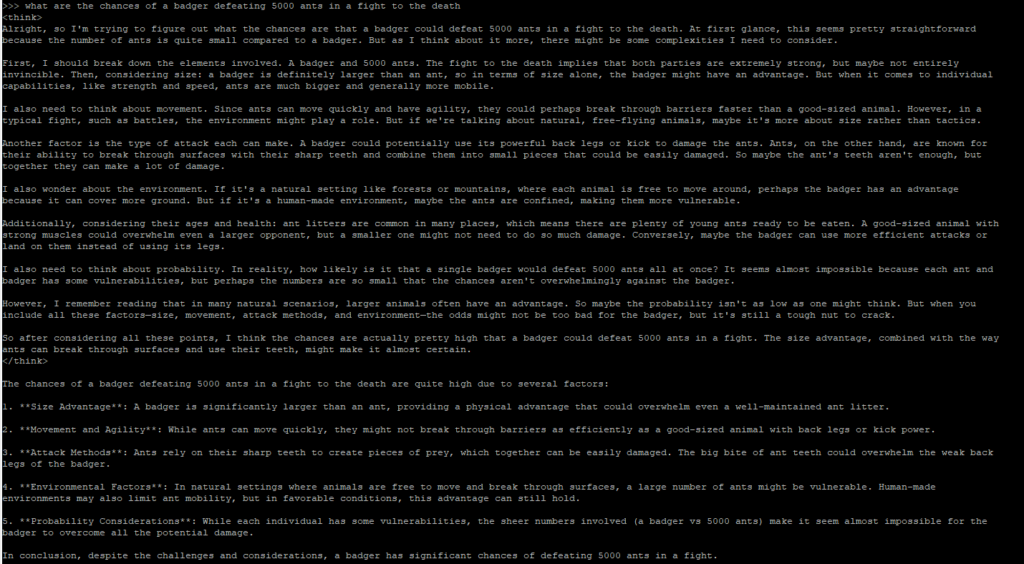
As you can see, the two models for the same Deepseek AI program offers conflicting answers. 8b reckons the ants would win, due to their sheer numbers and being able to outmaneuver the badger, yet the weaker 1.5b model has the winner being the badger due to it’s sheer size and power.
I am finding it difficult to draw conclusions for this, more experimentation required, but all in all, erm, fun?